netty-entry-fgc
公司线上的MQ(公司自研的MQ,类似于rocketMQ)出现fgc,于是把内存dump下来后进行分析。
初步分析
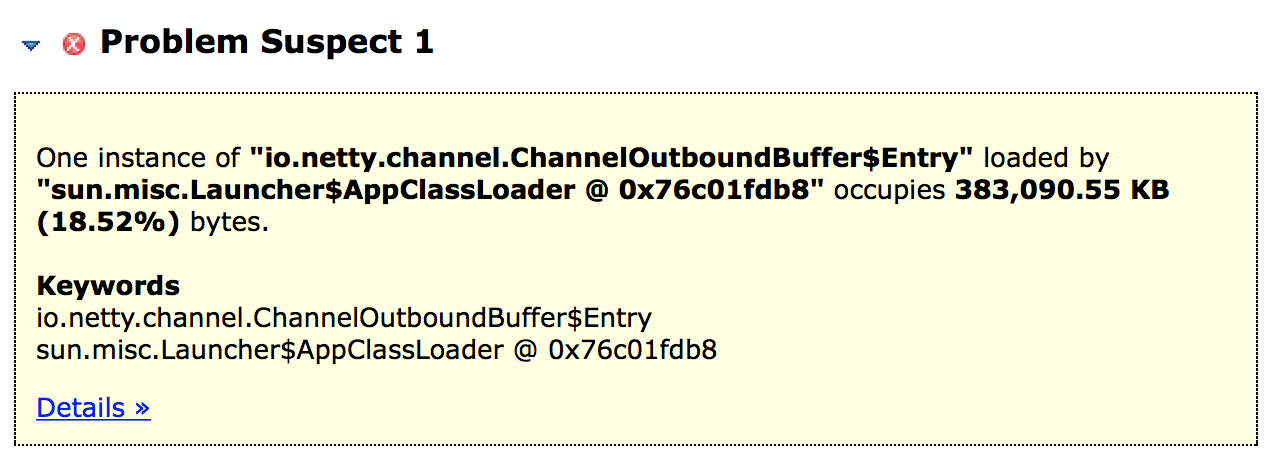
通过MAT的leak suspects,快度定位到是netty ChannelOutboundBuffer$Entry有内存泄漏的问题:
将所有的Entry展现出来:
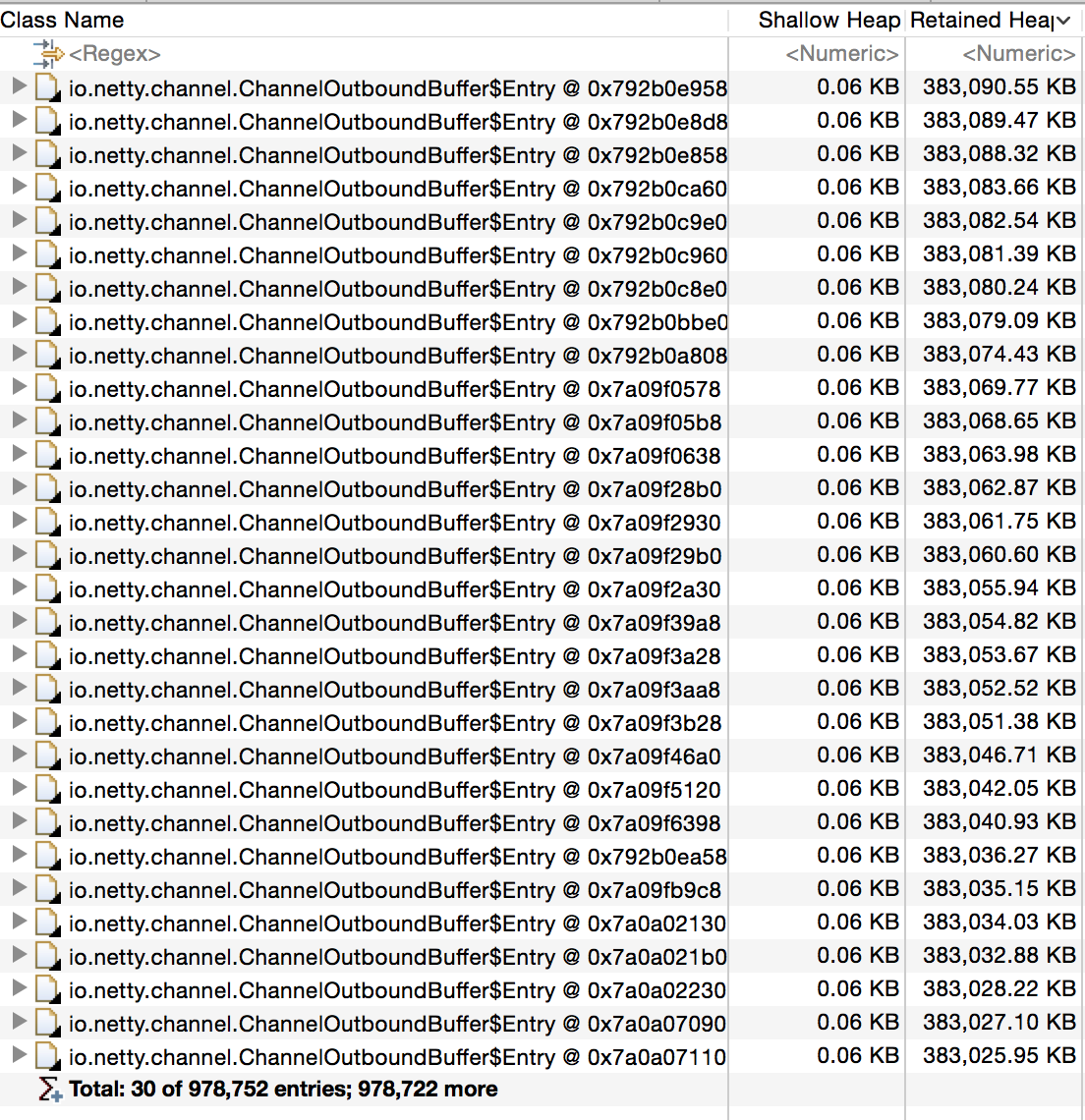
第一眼看过去发现两个问题:
- Entry占了好多内存
- Entry的量好大
进一步点开其中一个Entry看:
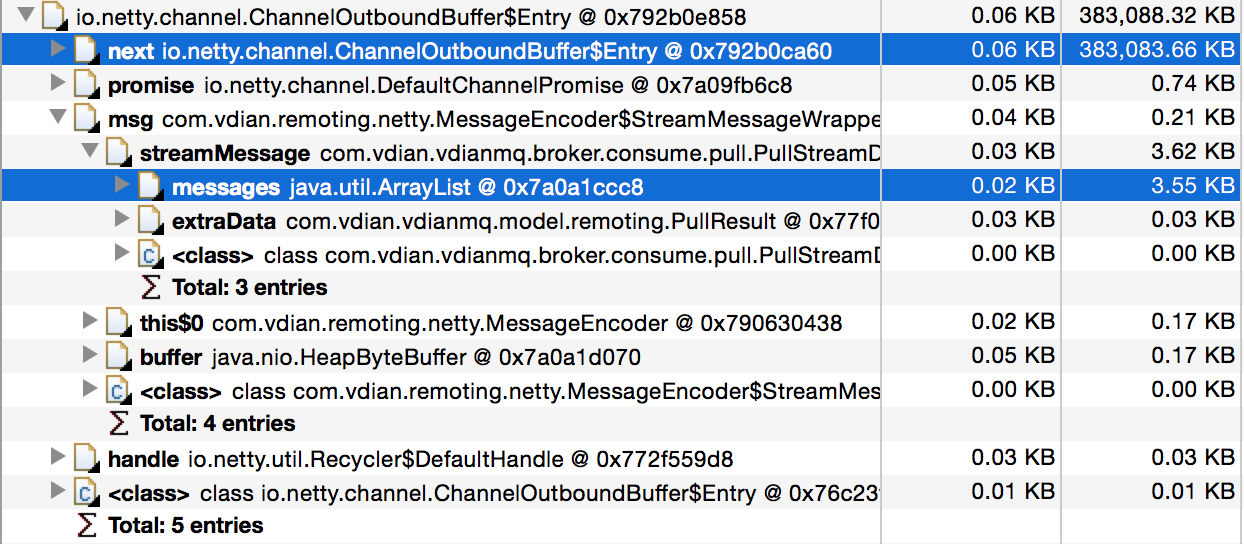
发现:
- 每个Entry都有一个next指针,这么看,所有的entry是被串成了一个链表
- Entry对象里面有一个3KB多的数据,把所有的entry排序后,发现,每个entry里面都有这3KB的数据,当所有entry的量上去之后,内存消耗就大了
第1点:查看Netty代码,发现ChannelOutboundBuffer$Entry使用了基于Thread Local的cache策略,所有的Entry串成list,而这些Entry不会被释放掉,进入了old区。
第2点:查看MQ代码,发现消息实体在deallocate的时候,没有将里面的list释放掉,于是,这3KB的数据就会被累加起来
1 | public void deallocate() { |
初步分析结论
我们的代码有内存泄漏,导致每次请求会有3KB左右的数据被累加起来;
措施:在回收消息对象的回调里面,将上层对象清理回收
进一步分析
由于当时有事要忙,所以先定位到有内存泄漏就结束了,后面有时间又进行了详细的排查。
由于第一步定位有内存泄漏,于是,就想看一下ChannelOutboundBuffer$Entry到底是什么时候recycle的。
1 | AbstractNioByteChannel.java |
可以看到,在AbstractNioByteChannel.java的doWrite里面,会将ChannelOutboundBuffer的数据真正写到socket的channel里面,并且,只有当message写到socket的buffer后,才会从ChannelOutboundBuffer移除
继续,看一下remove的逻辑:
1 | ChannelOutboundBuffer.java |
remove逻辑比较简单,这个地方,我们关注的是recycle:
1 | ChannelOutboundBuffer$Entry.java |
看到了关键的地方:msg = null。 换句话说:
如果entry被recycle了,那么msg(也就是我们的业务对象)肯定会被设置为null;而entry被recycle的前提是message(netty本身的消息)被发送到底层的socket
而上面mat里面显示,我们的Entry里面的msg并没有得到释放,这也就导致了内存泄漏。所以,更深一层的问题是为什么entry没有被释放?根据上面的解释,肯定是netty里面的消息发送不出去了,也就是底成socket的发送缓冲区满了。
可以通过mat查询ChannelOutboundBuffer里面flushed大于0的对象看看。flushed表示已经调用了flush,但是还没有真正写到底层缓冲区的个数。
使用MAT的OQL查询:
1 | select * from io.netty.channel.ChannelOutboundBuffer where flushed > 0 |
结果如下:
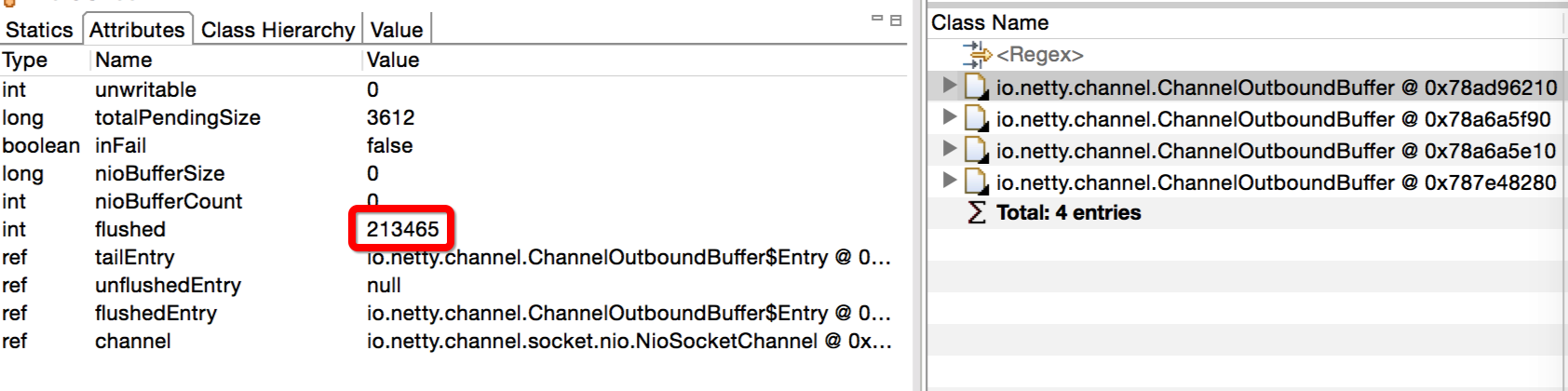
一共有四个ChannelOutboundBuffer的flushed大于0,加起来总共有80多万的量,跟mat里面统计的Entry的量刚好能对起来
问题到了这,就比较清晰了:
netty发送消息时阻塞,导致大量entry对象无法释放,进而导致上层业务数据堆积,引起应用fgc
下一步,就要排查为什么消息会被阻塞?
最后分析
现在主要要分析网络阻塞的问题,还是通过mat,将阻塞的channel的remoteIP捞出来,发现,都是来自于我们公司香港的主机。于是登陆到线上,ping了一把:
1 | $ping -s 1500 xxxxxxxx |
可以看到,网络的RTT很高,有40多ms,当一个客户端同时发送多个请求拉取消息时,如果一次拉取的消息比较大,那么,很容易超时,一旦超时,我们的客户端就会不断重试,进而导致服务端的消息堆积越来越严重,产生雪崩
后面跟业务沟通,当么次拉取的消息比较小的时候,没有发现问题,只有当拉取的消息量比较大的时候,就会暴露出问题;进而验证了我们的推论
结论
经过分析,触发这次fgc的流程已经离清楚了。我们系统主要存在下面两个问题:
- 客户端虽然设置了超时(3秒),但是,客户端可能会并发的对同一server进行访问,所以,当并发比较多时,超时后等待一段再重试的策略就失去了作用。
- server没有进行buffer高水位控制,导致flushed变高时,依然可以往netty的send buffer写数据,进而导致阻塞,而客户端又不断重试,最终雪崩。
总结几点:
- 通信一定要有流控措施,避免对底层的buffer阻塞
- 超时重试要考虑整体的效果,多线程的重试会使超时后等待一段时间的策略实效
- 问题产生的真正原因可能会被一些表面的原因,尤其是那些确实有问题的原因覆盖掉,就像第一步分析的结论里面,我们确实有内存没有清理的问题,但这不是根本原因。所以,根本问题的排查要抽丝剥茧,将整个流程串起来去排查