TCP短链压测被hang住问题排查
最近TCP模块在压短链,但是,压测的过程发现,每次压了几秒后jmeter就被hang住,无法继续发压。
问题发现
第一步先开始定位具体的问题。先dump了jmeter的线程,发现:
1 | "htw-tcp 1-100" #128 prio=5 os_prio=0 tid=0x00007f0cf822c800 nid=0x15dc1 runnable [0x00007f0c3f248000] |
所有的压测线程都是runnable状态,并且都在等待从socket read数据。我们使用的是BinaryTCPClient来压的短链,找源代码看了下:
1 | public String read(InputStream is) { |
从代码层面看,就是在一个短链的生命周期内,在read过程被阻塞住了:
1 | https://github.com/udomsak/JMeter/blob/master/src/protocol/tcp/org/apache/jmeter/protocol/tcp/sampler/TCPSampler.java |
这就会导致所有的线程被hang住,jmeter无法继续发压
问题定位
定位到具体的问题后,就开始找引起问题的原因。先抓包看了下:
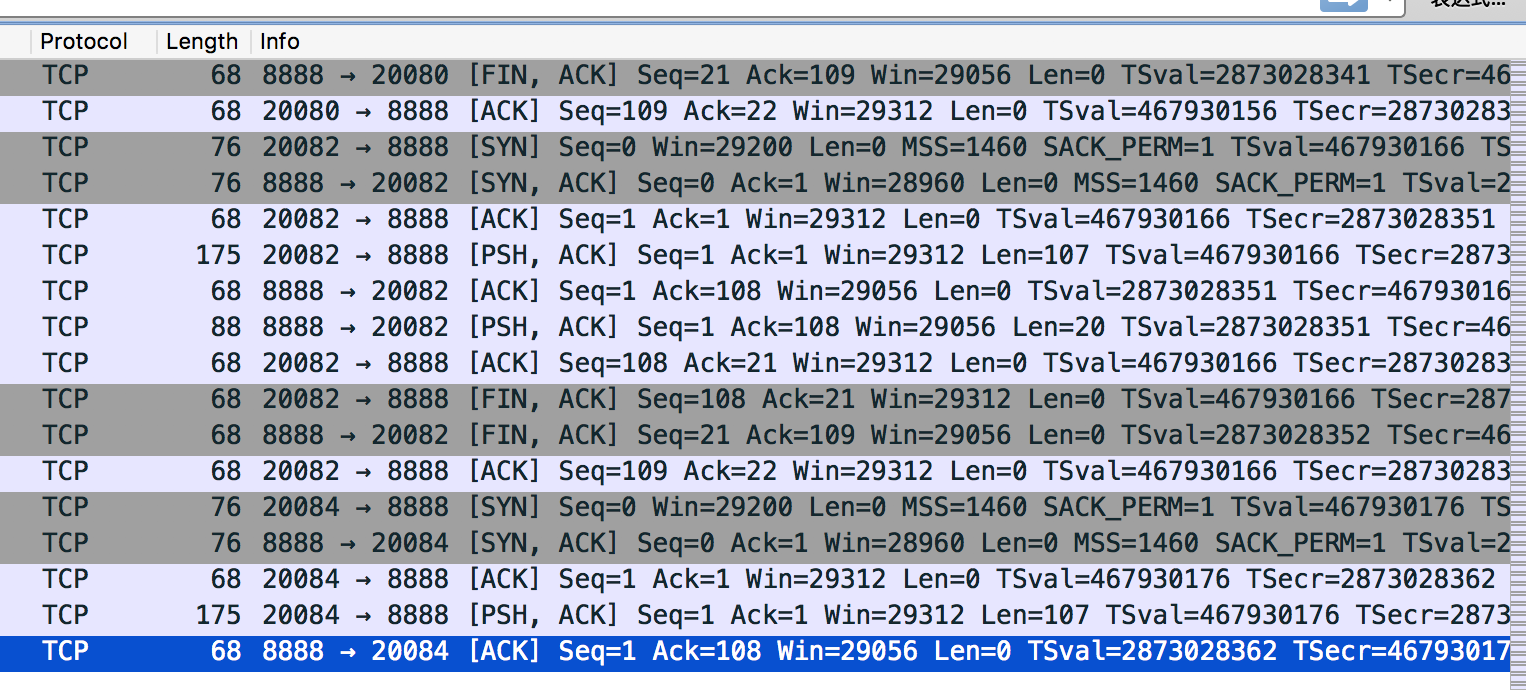
很奇怪,其他的每次短链交互服务端都会恢复一个response,但是到了最后一次(也就是被hang住的时候),服务端没有恢复response。服务端出了什么问题?
查看服务端日志,没有任何错误。
所以,刚开始没有认识到是服务本身的问题,以为是机器的tcp buffer问题。再查看了一些系统参数和状态后,发现系统没有问题。我们后面使用了一个线程来压问题还是必现。
所以,还是回到服务本身,既然没有报错,那就梳理了一下整个链路的日志,发现了有意思的现象。
原来,我们每次来了TCP的上行消息后,都会打一些日志:
1 | [INFO][2018-09-04T11:27:27.036+0800] channelInactive# Client: [{}]/10.90.28.18:52568 inactive 失效 |
这个是链接状态日志:
1 | [INFO][2018-09-04T11:27:27.047+0800] decode: 0200005C112345697599001100000000003C000001CE39A1072826AE000000000000180731122740300117310100E104000000BDE2020040E306006001820202E42001CC000058B50000AB432D58B50000F1A41A57170000DB711258BC0000C00C0FE704000000007D |
这个是decode日志。然后,后面就没有其他业务日志了。从这开始理了下业务代码:
1 | private void doDecode(ByteBuf in, List<Object> objects, ByteBuf dest) { |
发现在这里有异常被吃掉。基本嫩肯定是这里的问题了,因为看代码异常吃掉后,也没有按照协议来恢复一个response,刚好跟现象能够对应起来。
问题修复
修复有两个层面:
- 本质上,要修复业务流程,遵从协议规范,不要在一些异常流程下不回复response
压测的配置修改:压测程序不要一直等待服务端返回,设置一个可接受的超时时间。
<TCPSampler guiclass="TCPSamplerGui" testclass="TCPSampler" testname="htw心跳上报" enabled="true"> <stringProp name="TCPSampler.classname">org.apache.jmeter.protocol.tcp.sampler.BinaryTCPClientImpl</stringProp> <stringProp name="TCPSampler.server">10.90.23.28</stringProp> <boolProp name="TCPSampler.reUseConnection">true</boolProp> <stringProp name="TCPSampler.port">8888</stringProp> <boolProp name="TCPSampler.nodelay">false</boolProp> //设置超时时间 <stringProp name="TCPSampler.timeout">100</stringProp> <stringProp name="TCPSampler.request">${body}</stringProp> <boolProp name="TCPSampler.closeConnection">true</boolProp> <stringProp name="TCPSampler.EolByte">126</stringProp> <stringProp name="ConfigTestElement.username"></stringProp> <stringProp name="ConfigTestElement.password"></stringProp> </TCPSampler>
虽然我们总是强调不要吃掉异常,但在现实当中还是总是碰到这种情况,异常吃掉后对于问题的排查相对麻烦,需要引以为戒。