注意虚拟机时间漂移
最近业务反馈,他们消费MQ消息的时候,延迟很大,有一分钟多的时间,收到反馈后,我马上看了下MQ整个链路的时间
问题排查
根据traceId,把消息的每个步骤的日志拉出来看了下:
消息发送时间
1 | 2017-05-04 14:46:02,420|0029000001********17a450111|send_ok|t******operation|3|015F00030000****010C||4 |
消息存储时间
1 | //Thu May 04 14:47:19 CST 2017 |
消息消费时间
1 | 2017-05-04 14:47:19,804|00290000015bd2********0a017a450111|consume_ok|tp-consumer-group|t*******ration|3|015F0003000000****010C|12 |
问题排查
根据整个trace链路的日志,可以看出来,时间主要花在MQ Broker上,有1分多钟的时间消耗在存储上。这样看起来太不正常了,于是看了当时MQ broker的性能访问日志,没有发现MQ broker在存储的时候有大的RT波动。
既然MQ broker的性能日志显示没有问题,而trace链路显示的又存在很长的耗时,那问题出在哪儿?
没有办法,只好又梳理了消息(该场景下为事务消息)的整个流程:
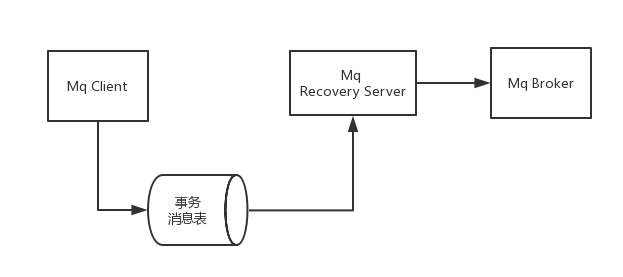
事务消息的流程里面,需要经历Mq-Recovery server来发送消息, 如果不是Mq broker的问题,那么最容易出现问题的地方就是这里了。幸好,Mq-Recovery server也有性能日志:
1 | 2017-05-04 00:14:18,974|query_messages|***|0|2 |
(最后一列是耗时)
可以看到,当时Mq-Recovery server访问事务数据库也没有时间消耗,排查到这里路又断了。。
问题定位
这个时候,我又想了下整个流程,发现即使有一些耗时操作,也不太可能有1分钟多的延迟,这个时候,我开始怀疑是机器时间的问题,虽然还没有确切的方向,但是,我决定对比下各个机器的时间
1 | date |
到每个机器都运行一遍,发现Mq-Recovery server的机器时间跟其他机器相比,延迟了有1分多钟,时间刚好跟消息的延迟时间对应起来,这么看来,问题应该就出在这里了。
那到底为什么机器时间延迟会导致业务消费消息延迟呢?
这个时候,马上去梳理下Mq-Recovery server发送消息的流程,发现了这样的代码:
1 | List messageWrappers = queryMessageLogs(System.currentTimeMillis() -taskConfig.getDelayScanTimeMs(), taskConfig().getBatch()); |
找到问题的根本原因了:Mq-Recovery server会依赖本地时间去计算一个扫描数据库的时间,用作延迟扫描,这个时候,如果本地机器的时间延后,那么,就会造成扫描数据库的时间延后
问题的解决
因为公司现在大部分机器都是虚拟机,而虚拟机不可能避免要遇到的问题就是时间漂移,所以在设计方案的时候,不要进行跨机器的时间比较, 如果要对数据库扫描进行延迟,可以利用数据库本身的时间函数:
1 | select * from table where gmt_create < date_sub(now(), INTERVAL 1000 second) |
其他感悟
排查问题的过程中,最重要的就是日志,把每个阶段的日志打印清楚,并且,要设计好整个链路的日志串联,还有,性能访问日志一定要加上