学习-微信红包后台系统可用性设计
最近阅读了一片文章:微信红包后台系统可用性设计实践, 主要讲了高可用的一些优化设计,以及如何平行扩所容,细节可以看看原文,我这里主要讲一些我的一些理解。
异步化改造
一个系统越复杂,可用性越难保证,在追求高可用的时候,需要梳理整个链路,找出关键路径,然后,其他的非关键路径采用异步的方式,最终结果通过对账等系统保证最终一致。
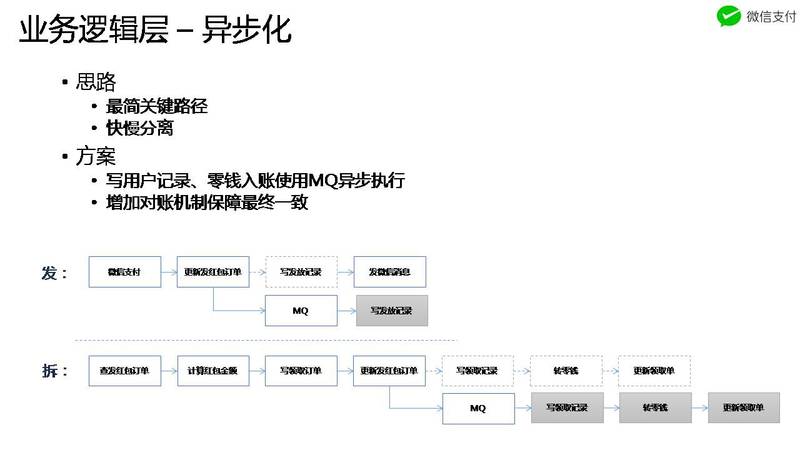
如上图所示,原来的整个链路比较长,但是,结合红包业务,梳理出来关键路径后,就简化了好多。这个地方要注意的是,非关键路径并不是不重要,而是结合当前业务看,在当前的场景没有必要马上处理,最终我们还是要保证一致性的。
单元化
这点感触比较深。下面是微信红包原来的架构,我们好多系统也是这种架构。这种架构下,上层server无状态,可以动态扩缩容,但是不好的地方在于:DB是同一套,一个DB挂了,就会拖累所有的上层server。
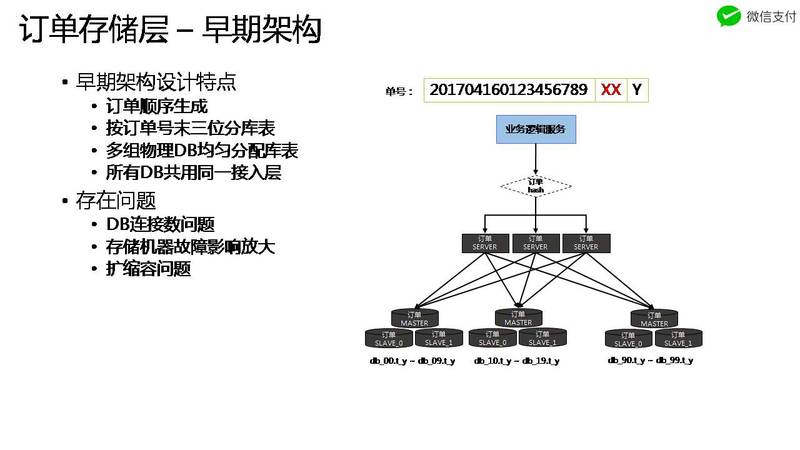
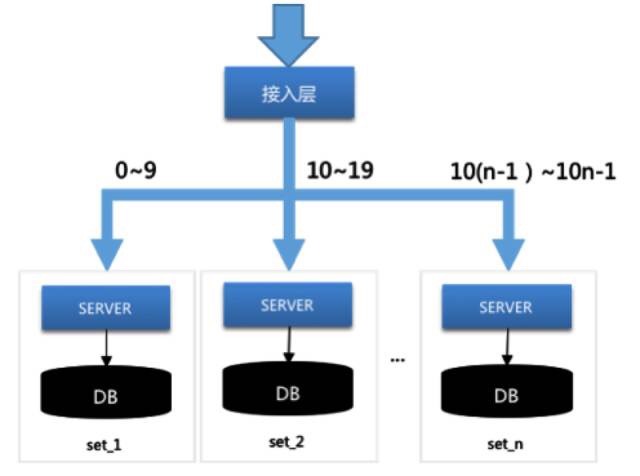
而如果通过单元化(微信里面叫set),将server,db纵向切分成不同的单元,就可以应付某个物理DB挂了场景。该解决方案的关键在于:
- 物理隔离,整个链路上的物理隔离。这样,某一个物理机房,物理DB挂了,不回影响全局
- 流量沾粘(stick),按照统一的规则将同一个流量纵向分配到同一个单元。规则的设计也很重要,后面会讲。
平行扩缩容
对于一个无状态的server而言,扩所容没什么问题,但是,碰到DB或者MQ(broker)这种本地有状态的场景就比较难搞了。
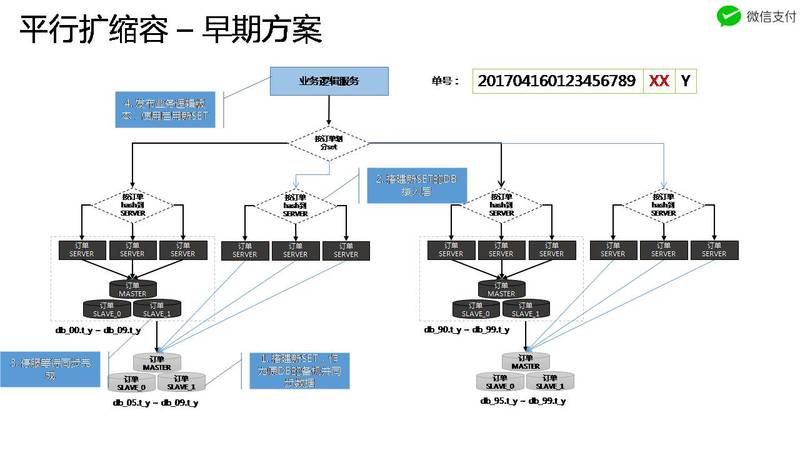
对于有状态的扩容缩容,面临的问题主要是:
- 绑定关系变了。本来这个请求根据Hash规则,落在机器1,扩容后,这个请求被分配到了机器2。
- 数据要进行迁移。本来在机器1上的数据,要迁移到机器2上面。
对于第一个问题,解决的大概方案基本都是一致性Hash,但是第二个问题就没有统一的方式了,并且,要解决第二个问题,不论什么方案,数据的迁移都是耗时耗力的事,所以,最好的方案就是:不进行数据迁移
看看微信红包最开始的方案(这是一个很常见的方案),这个方案就是利用红包后面两位来hash到不同的set,一旦要扩容所容,就需要把老机器的数据往新机器上迁移。
更好的方案怎么做?
很容易想到的好的方案就是:新数据迁移到新的集群,老数据依然在老的集群。 如果能这样的话,老数据就不需要迁移了。
微信红包的第一个方案不能实现这样的效果,原因是这个方案无法区分新老数据(这个地方的区分,是指切分流量)。比如,老红包:1231__09__1, 新红包: 8888__09__1(09用来划分set,后面的1是分表),新老两个红包数据都落在一个set,扩容后,两个红包都会落在新的set。那边老红包的数据势必要迁移过去。
下面是新的微信红包的方案:
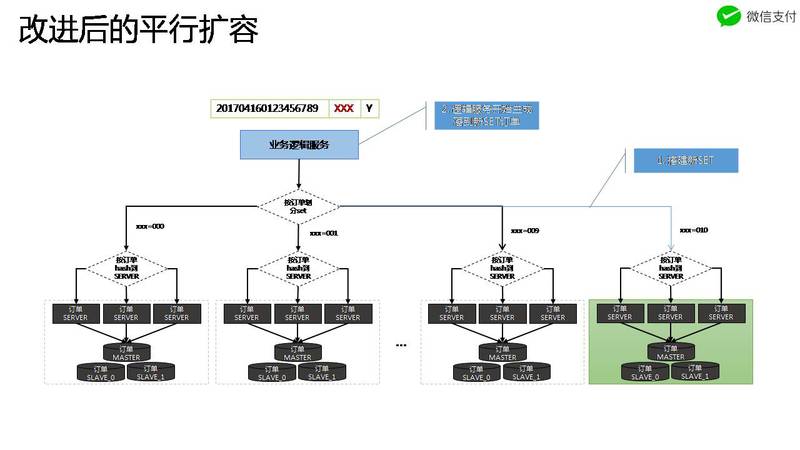
该方案,预留出三个位置用来标示单元,关键是:新的数据可以使用新的值,这样,就可以把新老数据区分开。比如,老红包:1231__001__1, 新红包: 8888__111__1, 因为111这个位置以前没有分配过,所以,只要是111的红包就可以分配到新的集群,而老的红包数据不动
所以在设计的时候,就要考虑好扩容所容的问题,预留好槽位,以便区分新老数据。
微信红包的ID
注意到一个细节,微信红包的设计里面,ID有两部分组成:
全局唯一的ID + (分单元字段+分库分表字段)
前半部分是全局唯一的一个ID,后面是一个可变的字段,主要作用是用来分区,分库,分表。这样设计的好处在于,后面部分的字段可以任意变换,而整体上红包的ID仍然是唯一的,这就为后面的扩展做好了铺垫
冷热数据
海量数据的解决方案就是要做冷热分离,问题的关键是如何优雅的将冷数据导出去?
分库分表, 双维度分库分表:按照业务字段解决容量问题,按照时间解决冷热数据问题
秒杀
其他的一些技术跟设计一个秒杀系统类似:
- 分层校验:尽量把请求拦在前面
- 削峰:想尽办法把流量打散,例如:答题,开红包等
- 排队:最终落入DB前进行排队,一方面避免对DB压力,一方面保证先到先得