flink实时分析的几点总结
最近在折腾公司打点日志(trace跟踪日志,类似阿里的鹰眼)的实时分析,大概总结一下。
实时流处理的技术越来越成熟,相对于spark而言,flink的模型已经抽象的很好;幸好我是从beam开始切入了解流处理的,现在回头看一些spark以及spark stream,flink的概念就很好懂了。
流处理基本概念
如果你想了解流处理,一定要看下面两篇文章:
看完之后,就可以理解流处理的中两个核心问题之一:时间,另外一个是正确性(Correctness).关于正确性的了解,可以看几篇flink发的paper,写的都很好,比官方文档里面介绍的要详细一些,例如:
- State Management in Apache Flink: paper里面讲了flink的state管理,以及分布式快照的思路(很值得借鉴)
细节可以慢慢看,我这里简单总结一下。先了解流处理里面最基本的两个概念:
- processing time: 系统接收数据进行处理的
- event time: 数据(事件)本事发生的时间。
在一个分布式的系统里面,延迟,网络异常,时间漂移等等,会造成两个时间对应不起来,发生乱序。而一个好的流处理框架,应该能够很好的处理这种情况。
流处理在我提到的那两篇博客里面,被总结起来就是处理WWWH的问题:
What results are calculated?
我们要做何种计算?想要什么样的结果?这个是最好理解的,毕竟要处理数据嘛,聚合也好,求极值,求平均等等,我觉得这个是数据处理理解起来最简单的一个概念。
Where in event time are results calculated?
流处理的核心就是一堆无穷无尽的数据流,那问题就是:总归要有个界限,让我们去计算这些数据:这就是window的目的。窗口就是给数据一个边界,在窗口内部的,我们才去计算。
When in processing time are results materialized?
这个问题是流处理里面最不容易理解的,就是我们计算的结果何时写出去?造成这个问题的根本原因就是分布式的网络环境下,采集上来的数据的时间是不一致的,那么,我们怎么知道当前的这个窗口已经采集完了数据可以计算输出结果了呢?flink里面(包括beam)都是采用了watermark和trigger的机制。watermark可以理解系统定期(按照一定频率)输出一条水位线,当然,这个水位线的值可以我们自己根据采集的数据来计算得出;然后,当水位线滑出窗口的尾部(end)的时候,输出窗口数据,这就是默认的trigger机制。Beam里面还描述了其他的trigger机制:例如基于数量的,一个window收集了指定数量的数据就输出。
即使有了水位线和trigger机制,还是不可能出现理想的情况:一个窗口等所有的数据都到齐了才输出,一方面内存扛不住,另一方面也没有意义,毕竟实时流处理关键在于实时。那么,既然没法理想的收集所有的数据,就会面临一个问题:那些迟到的数据怎么办?flink简单直接:丢弃。(允许一个时间阀值)
How do refinements of results relate?
这个是涉及到输出,比如,我们定义了两个trigger策略:一个是收集到100个数据就输出一次结果,另外一个是等一个小时输出。那么,同一个window的多个pane(一个trigger一个pane)之间的结果是如何关联的?是trigger一次清理一次呢?还是trigger之后累积起来?flink里面可以根据trigger的返回值来决定具体的策略。
我们的流处理
上面简单介绍了流处理的概念,当然,还有其他方面的:数据的正确性,运行时任务分配等等,可以看看flink的官方文档。下面,介绍下我们的流处理结构。
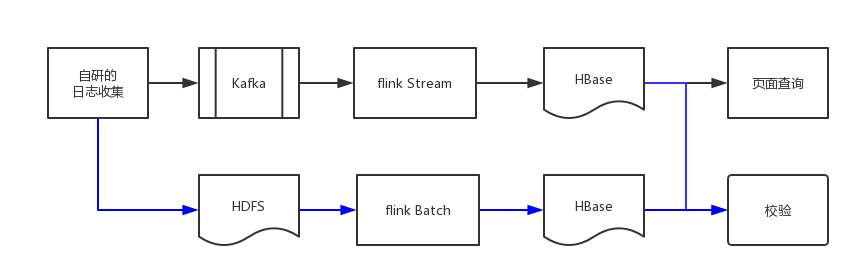
整个结构有两个部分:实时流程和批处理流程。实时流程主要用于实时的分析,而批处理流程则用于数据的校验和修正,因为我们的实时流程基于日志的event time,日志可能乱序,丢失,较大的延迟到达(我们自研的日志收集还处于完善阶段),因此有必要增加一个校验和修正的流程。
具体的实时计算逻辑,在前期包括:
- 均值,最大值,最小值,qps,count,错误采样,超时采样等
- 方差和分位数
每个统计都包括应用,服务,方法几个维度,按照每分钟粒度进行统计。第1列的指标其实还好统计,关键是第2列的两个指标。后面会详细讲到。
遇到的几个问题
水位线怎么不触发?
处理逻辑写好,sink写好,等着看数据输出,结果发现数据一直输出不出来,打日志看source也有数据进来,那问题出在哪儿呢?
1 | EventTimeTrigger.java |
看了下eventTrigger的代码(其实前面也讲过),只有当当前的水位线越过窗口(时间大于窗口的timeStamp)才会触发Fire的操作。我们的处理流程没有触发,那就说明我们的水位线没有更新到合适的值。
1 | BoundedOutOfOrdernessTimestampExtractor.java |
最开始我使用了BoundedOutOfOrdernessTimestampExtractor,允许一个乱序的时间周期(1分钟),debug看确实发现lastEmittedWatermark有更新,这说明这个地方是触发了Watermark的值,不过debug的过程中,发现时不时会出现这样一条水位线:
Thu Jan 01 07:59:59 CST 1970
这个时间线肯定不对,那如果出现这么一条水位线flink会怎么处理?
1 | SystemProcessingTimeService.java |
看到这,觉得及时出现了一条这样的水位线,也不影响,因为TimestampsAndPeriodicWatermarksOperator会做判断:如果新的水位线小于当前的水位线,就不会更新了(官方文档也是这么说的). 那问题出在哪儿?没办法,继续扒flink的源码看。
终于,顺着StreamInputProcessor–>StatusWatermarkValve理了下来,看见这样的处理逻辑:
1 | StreamInputProcessor.java |
可以看见,在这里有个逻辑,会将所有的channel status的水位线做个汇总:取最小的水位线。那是不是问题出在这里?后面debug了下看看,确实,这个地方有的channel status下的水位线一直是1970的那个不正常的水位线,进而导致整体的水位线发送不出去。两个问题:
- channel status什么鬼?这里设计到inputGate,inputChannel的flink运行时概念,具体可以看看这些资料.1,2
- 那个1970年的水位线是怎么产生的?理了下flink的代码,flink会有一个类似定时器的任务,定期获取当前的每个inputChannel的水位线,而如果当前的channel没有数据,或者数据延迟很大,就会拖住整个inputGate的水位线,进而拖住后面的算子,导致流产走不下去了。这个问题后面还有一点讨论,目前先到这。
关于方差和分位数
这类问题统一归类为计算逻辑,通过这次实时处理的实践,发现好多我们常见的算法其实不适合在实时流处理里面实施,比如:
- 常见的方差算法:依赖于平均数,而我们不可能等到一个窗口的数据都到达才进行计算,这样内存会扛不住,而是每来一个元素迭代计算。
- 分位数计算:一样的问题,我们不能等所有的元素都到齐。
分位数后面选择了Naive算法,详细介绍, 而分位数算法就比较难搞了,一个好的分位数算法必须满足:
- 少的内存消耗
- 支持merge操作:这点很重要,流处理的基本模型就是按照分区分开计算,再合并。那么,分位数算法也要支持merge操作。
实际上,第二点还是很难做的,在google里面找了好几篇paper看了下,没有特别理想的,下面推荐一个看起来不错的:
里面有支持merge的分位数算法,唯一的缺点就是内存还是有点大。
关于late data
前面简单介绍了late data的产生原因:我们的窗口不能就那么一直等着所有数据都到达,窗口总是要关闭的。flink的处理逻辑:
1 | WindowOperator.java |
flink直接不再处理这个元素(丢掉了),另外,判断是非late的函数:
1 | protected boolean isWindowLate(W window) { |
这个地方需要注意的是,在eventTime模式下,判断的依据是当前的水位线, 那如果水位线更新不正确,就像第一个问题那样,内存要小心了。
关于水位线的进一步思考
前面水位线的问题可以看出来,flink在一个分区结果集合内(ResultPartition),总是获取最小的水位线,那么, 我们的处理流程就会有问题。
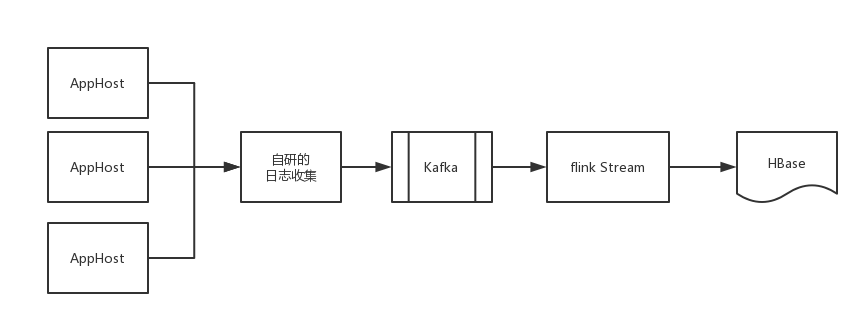
我们收集的日志的宿主机器,可能随时加入或者退出(扩容或者缩容),收集的任务也可能失败,重启等等,这就可能会出现这样的场景:
- 一部分数据(或者说大部分)是OK的,例如,event time进行到2017-09-20-12:00:00,当前的水位线就是:2017-09-20-12:00:00
- 然后,来了一批相同key的数据,不过event time在 2017-09-20-12 06:00:00(或者更早),这是有可能的,比如,新加了一台机器,但是这台机器忘了部署我们收集日志的客户端;或者这台机器的任务收集挂了, 我们好久才发现等等
假如,第二批数据恰好跟第一批数据落在一个inputGate(前面的连接有介绍),那么,整个inputGate的watermark将不会更新(取所有channel最小的),一方面会造成数据输出不出来,另一方面,也会造成内存的消耗。
这一点,让我想到,我们在做实时流处理的时候,一定要整体链路考虑,从数据源的产出到数据结果的输出,这个链路往往比较长,要认真梳理每个环节出现的各种情况。
具体到我们的场景,我们采取的方案就是在产出watermark的时候,做了一个修正:
1 | public Watermark getCurrentWatermark() { |
这个修正基于当前时间,这个修正会导致第二批数据不参与运算,但是可以接收,毕竟,我们要求的是实时处理。