最近在参考阿里的rocketMQ来优化我们自己的mq,发现一段有意思的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 MappedFile.java public AppendMessageResult appendMessage(final MessageExtBrokerInner msg, final AppendMessageCallback cb) { /** * 奇怪的地方在这里 /* ByteBuffer byteBuffer = writeBuffer != null ? writeBuffer.slice() : this.mappedByteBuffer.slice(); byteBuffer.position(currentPos); AppendMessageResult result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, msg); this.wrotePosition.addAndGet(result.getWroteBytes()); this.storeTimestamp = result.getStoreTimestamp(); return result; }
网上一搜就会搜出来对rocket的源码分析,例如 ,他们都会分析rocketMQ的源码,但是没有给出为什么?
RocketMQ的MappedFile
方式
写入
落盘
方式一
写入内存字节缓冲区,direct类型(writeBuffer)
从内存字节缓冲区(write buffer)提交(commit)到文件通道(fileChannel),fileChannel flush到磁盘
方式二
写入映射文件字节缓冲区(mappedByteBuffer)
mappedByteBuffer force到磁盘
有意思的是方式一:数据写入到mmap出来的mappedByteBuffer,而是写到一个DirectBuffer里面,然后commit到fileChannel里面,再由fileChannel刷盘。why?随便一搜mappedByteBuffer的资料都是说mmap之后速度有多快,那为什么还要多了方式一这条路?
其他问题 除了上面提到的问题之外,还有其他疑问:
仔细看MappedFile的代码,会发现消费的时候,依然读的mappedByteBuffer,难道fileChannel write之后mappedByteBuffer会马上看到?
在使用mmap的同时,又使用directBuffer来写数据,liux怎么管理两份内存的?
这样写,有什么优势?(上面的问题)
下面就来慢慢的理这几个问题。
问题一:MappedByteBuffer和FileChannel关系 简单点说,MappedByteBuffer通过FileChannel mmap )出来之后, 两者就没有太大关系了,官方文档是这么说的:
A mapping, once established, is not dependent upon the file channel that was used to create it. Closing the channel, in particular, has no effect upon the validity of the mapping.
还有:
This method is only guaranteed to force changes that were made to this channel’s file via the methods defined in this class. It may or may not force changes that were made by modifying the content of a mapped byte buffer obtained by invoking the map method. Invoking the force method of the mapped byte buffer will force changes made to the buffer’s content to be written.
简单点说,mmap之后,MappedByteBuffer访问的是一块内存,跟原来的文件之间的同步是不确定的,这就需要看底层的os是什么时候刷新数据和请求数据了。RocketMQ里面,需要控制read的位点:
1 2 3 4 5 6 7 /** * @return The max position which have valid data */ public int getReadPosition() { return this.writeBuffer == null ? this.wrotePosition.get() : this.committedPosition.get(); }
可以看到,获取数据的时候,如果使用了directBuffer,那么,读的位店依赖于commit的位点,只有directBuffer的内存被commit之后,才会被消费。
问题二:内存管理 这是个很深的坑,我这里简单总结下。
MappedByteBuffer 想更深入的了解MappedByteBuffer,需要查一些linux的内存机制,这些资料很多,我找了一个还不错的:
操作系统会那一部分当作page cache来用,以加速对文件的访问,因为不需要在内核空间和用户空间复制了。我们的程序,本质上都是从文件加载过来的(当然,可以通过网络channel),例如,我们可以通过 pmap 查看我们的程序内存有哪些占用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 $pmap -x 32024 32024: ***** Address Kbytes RSS Dirty Mode Mapping 0000000000400000 4 4 0 r-x-- java 0000000000600000 4 4 4 rw--- java 0000000000feb000 3132 3080 3080 rw--- [ anon ] 00000006b0000000 5505024 1935360 1935360 rw--- [ anon ] 0000003fc3200000 128 116 0 r-x-- ld-2.12.so 0000003fc341f000 4 4 4 r---- ld-2.12.so 0000003fc3420000 4 4 4 rw--- ld-2.12.so 0000003fc3421000 4 4 4 rw--- [ anon ] 0000003fc3600000 1576 672 0 r-x-- libc-2.12.so 0000003fc378a000 2048 0 0 ----- libc-2.12.so 0000003fc398a000 16 16 8 r---- libc-2.12.so 0000003fc398e000 4 4 4 rw--- libc-2.12.so 0000003fc398f000 20 20 20 rw--- [ anon ] 0000003fc3a00000 8 8 0 r-x-- libdl-2.12.so 0000003fc3a02000 2048 0 0 ----- libdl-2.12.so 0000003fc3c02000 4 4 4 r---- libdl-2.12.so 0000003fc3c03000 4 4 4 rw--- libdl-2.12.so 0000003fc3e00000 92 72 0 r-x-- libpthread-2.12.so 0000003fc3e17000 2048 0 0 ----- libpthread-2.12.so 0000003fc4017000 4 4 4 r---- libpthread-2.12.so 0000003fc4018000 4 4 4 rw--- libpthread-2.12.so 0000003fc4019000 16 4 4 rw--- [ anon ] 0000003fc4600000 28 20 0 r-x-- librt-2.12.so 0000003fc4607000 2044 0 0 ----- librt-2.12.so 0000003fc4806000 4 4 4 r---- librt-2.12.so 0000003fc4807000 4 4 4 rw--- librt-2.12.so 0000003fc4a00000 524 20 0 r-x-- libm-2.12.so 0000003fc4a83000 2044 0 0 ----- libm-2.12.so 0000003fc4c82000 4 4 4 r---- libm-2.12.so 0000003fc4c83000 4 4 4 rw--- libm-2.12.so 0000003fc6e00000 88 16 0 r-x-- libgcc_s-4.4.7-20120601.so.1 0000003fc6e16000 2044 0 0 ----- libgcc_s-4.4.7-20120601.so.1 0000003fc7015000 4 4 4 rw--- libgcc_s-4.4.7-20120601.so.1 00007f9de5758000 12 0 0 ----- [ anon ] 00007f9de575b000 1016 96 96 rw--- [ anon ] 00007f9de5859000 12 0 0 ----- [ anon ] 00007f9de585c000 1016 100 100 rw--- [ anon ]
也可以通过proc文件下查看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 cat /proc/5791/smaps 7ec2df680000-7ec31f680000 rw-s 00000000 08:10 43779827 /data1/vdianmq/store/message/000001977832439808 0 Size: 1048576 kB Rss: 16368 kB Pss: 16368 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 16368 kB Private_Dirty: 0 kB Referenced: 16368 kB Anonymous: 0 kB AnonHugePages: 0 kB Swap: 0 kB KernelPageSize: 4 kB MMUPageSize: 4 kB
可以看见基本有两类:一是带文件句柄的,另一类是[anon]的;第一类就是mmap了一个文件的,另一类就是通过程序自己申请,比如,new了一个块directBuffer,也就是后方没有文件支撑的。这两类的细节就不说来,刚兴趣可以搜一下[linux swapness]这个参数的资料,就会涉及到这个话题。
总的说了,通过mmap得到的MappedByteBuffer,会作为page cache的一部分来用(这一点很重要,后面还会讲)。
通过触发page fault来读取文件,细分又有:minor page fault和 major page fault。资料 . 可以通过sar来查看:
1 2 3 4 5 sar -B 1 06:02:45 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff 06:02:46 PM 768.32 7409.90 2726.73 7.92 6984.16 0.00 0.00 0.00 0.00 06:02:47 PM 0.00 8561.62 2953.54 0.00 7978.79 0.00 0.00 0.00 0.00 06:02:48 PM 510.20 8102.04 2904.08 4.08 7959.18 0.00 0.00 0.00 0.00
除了主动刷回外,底层的操作系统也会定期刷到文件里面,可以通过调节下面的参数来调整:
1 2 3 4 5 echo 'vm.min_free_kbytes=5000000' >> /etc/sysctl.conf echo 'vm.dirty_background_ratio=50' >> /etc/sysctl.conf echo 'vm.dirty_ratio=50' >> /etc/sysctl.conf echo 'vm.dirty_writeback_centisecs=360000' >> /etc/sysctl.conf echo 'vm.swappiness=10' >> /etc/sysctl.conf
FileChannel和DirectBuffer Java nio肯定比Java io要快,主要因为java nio是基于block的传输,将数据聚合(cache)成block再写到磁盘(或者读取),速度自然比基于字节的流要快。
采用DirectBuffer之后,通过Java写文件效率会高一些.
因为Java GC的缘故,当我们通过FileChannel写文件的时候,如果不是使用DirectBuffer,Java会开辟一个DirectBuffer来缓存数据,以防止GC造成的数据移动。下面是Java的源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 sun.nio.ch.IOUtil.write static int write(FileDescriptor fd, ByteBuffer src, long position, NativeDispatcher nd) throws IOException { if (src instanceof DirectBuffer) return writeFromNativeBuffer(fd, src, position, nd); // Substitute a native buffer int pos = src.position(); int lim = src.limit(); assert (pos <= lim); int rem = (pos <= lim ? lim - pos : 0); ByteBuffer bb = Util.getTemporaryDirectBuffer(rem); try { bb.put(src); bb.flip(); // Do not update src until we see how many bytes were written src.position(pos); int n = writeFromNativeBuffer(fd, bb, position, nd); if (n > 0) { // now update src src.position(pos + n); } return n; } finally { Util.offerFirstTemporaryDirectBuffer(bb); } }
看来,使用DirectBuffer确实有好处,那么,使用了DirectBuffer之后,写文件操作的后续流程是怎么样的呢?
(网上扒了一个图)
后续还是很麻烦:我们依然要经过linux的page cache,然后,才sync到磁盘。我们使用了DirectBuffer,只是避免了JVM 堆内存的一次拷贝,其他的流程被没有省。更多的细节可以去深入了解下page cache。
还有必要提的一点是,数据到了page cache,那什么时候写到disk呢?大概有三种方式:
no write
write through
write back:linux的机制,对我们影响最大,我们要定期sync到磁盘
详情可以查看这篇论文
串起来 将上面的内容串起来:
FileChannel的写入和MapperByteBuffer的写入只能有一个在起作用。原因是他们各自为政,各自只能刷新自己的内容
mmap出来的MapperByteBuffer会作为page cache的一部分
FileChannel结合DirectBuffer会提高写入性能,避免了堆内存的一次拷贝
FileChannel写DirectBuffer之后,数据就到了PageCache里面,或者自己sync,或者依赖操作系统的刷新策略
FileChannel写DirectBuffer之后,数据就到了PageCache里面,就到了MapperByteBuffer里面,因为MapperByteBuffer被用作了文件的cache
关于第5点,我们可以验证一下:
1 2 3 4 5 6 7 ByteBuffer byteBuffer = ByteBuffer.allocateDirect(7 * 1024); byteBuffer.put(data); mappedByteBuffer.put(data); sleepForAWhile(); mappedByteBuffer.force(); sleepForAWhile(); fileChannel.write(byteBuffer);
先写mappedByteBuffer,然后将数据刷新到磁盘,这个时候通过 pmap 查看进程的内存:
00007fd4e8600000 10240 4 0 rw-s- /tmp/1
刚开始,进程所占的文件的cache里面,dirty为0,然后,fileChannel写入后,dirty发生了变化:
00007fd4e8600000 10240 4 4 rw-s- /tmp/1
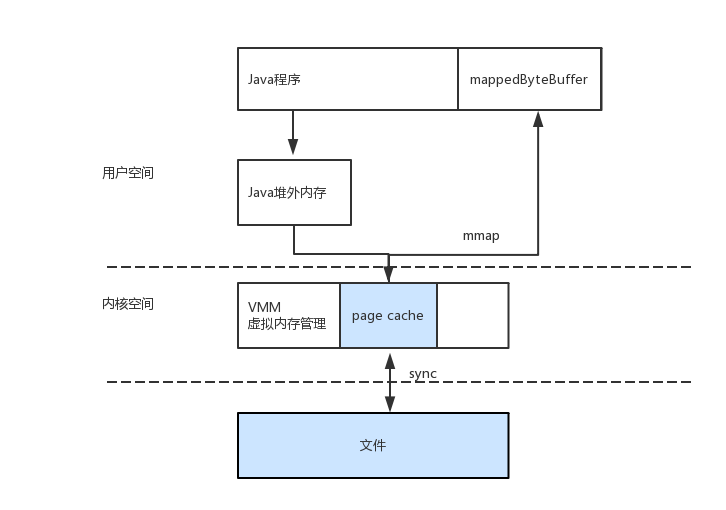
验证了我们的流程:directBuffer被写入到了MapperByteBuffer(本质是,用户空间的数据,被写到了系统的page cache里面)。
下面是整个流程:
根据这个流程回过去验证rocketMQ的代码,基本都可以验证通过,除了一点,这个流程好在哪儿?
结论 rocketMQ的使用这个流程就意味着,FileChannel+DirectBuffer的组合比MapperByteBuffer要好,但是,我搜了一堆资料,都没有明显的说明,除了在wiki 看到了这么一句:
The memory-mapped approach has its cost in minor page faults—when a block of data is loaded in page cache, but is not yet mapped into the process’s virtual memory space
关于Page Fault的资料可以去搜一下。wiki里面提到的一点就是,MapperByteBuffer有一个缺点就是minor page fault的代价。但是,根据我们上面的分析,会发现,整个流程也一样会触发 page fault:因为也会写入到 page fault。不过RocketMQ做了一层优化就是 批量commit,每次累计一组page之后才commit一次:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 protected boolean isAbleToCommit(final int commitLeastPages) { int flush = this.committedPosition.get(); int write = this.wrotePosition.get(); if (this.isFull()) { return true; } if (commitLeastPages > 0) { return ((write / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE)) >= commitLeastPages; } return write > flush; }
能从代码看出来的优势就这么点了。另外,具体就要压测看看效果了,因为,wiki里面还提到了:
In some circumstances, memory mapped file I/O can be substantially slower than standard file I/O. 资料
然后,反过来看这次问题的查找,关键在于理清楚Java FileChannel和Linux PageCache的关系,网上大部分资料都是将两个分开讲,没有像RocketMQ这样,合起来用,看来RocketMQ的性能优化已经到了很细致的地步了。