内网HTTP请求触发限流的排查
最近在做全链路的压测,当前晚上压测的时候,总是触发第三方业务的限流机制,虽然我们确实压的流量比较大,可以跟第三方简单沟通后,没有找到一个确切的原因;后面经过排查理了一个大概的思路,下面就讲一下具体的问题。
先看一下我们的整个流程(简化版的),如图:

我们的业务通过HTTP访问接入层,接入层部署了10台nginx集群,经过nginx的负载均衡后再请求第三方业务。
单机限流
首先,第三方配置了限流规则,比如:每秒2000qps,这个值乍看其实挺大的,但是,一般而言接入层都是单机限流,所以,10台ngxin,分给每台nginx的流量就是:200qps,也就是单机只能通过200qps。
Nginx限流模型
具体的可以在网上找到更详细的资料,这里大概说下,nginx的限流是通过req_limit来实现的,核心的代码如下:
1 | ms = (ngx_msec_int_t) (now - lr->last); |
大概的含义就是:
- nginx针对每个request来计算是否触发限流
- 每来一个请求,都会将我们配置的限流大小(limit)在累计时间内求出一个平滑的限流大小;例如,我们配置的限流是1000,当前请求距离上一次请求的时间差是100ms,那么,当前允许通过的流量限制是:1000*(100ms/1s) = 100.
- 如果超出了平滑后的limit限制,就会使用burst值。burst是一个缓冲,允许一定程度的突发流量。比如,如果配置了burst是70,那么,当前流量超过了100的limit后,还会再接收70的突发流量。
所以,我们不能单纯的看配置的每秒的限制规则,应该看流量是否是平滑的流量,如果流量有突变,是否超出了burst的值。
HTTP长链接更容易触发限流
HTTP1.1之后大家使用的长链,也都习惯觉得长链好,确实,长链会避免频繁的握手耗时,但是,在我们的内网模型下,却很容易触发单机限流。如下图,一般而言,相对于中台的接入层,业务一般部署的机器是会比较少: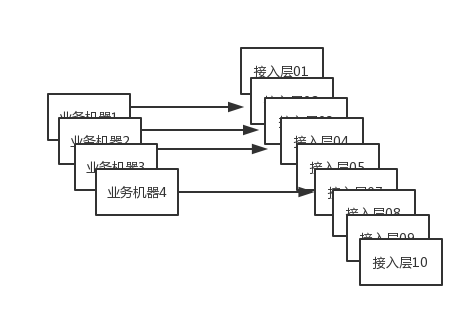
另外现在接入层的限流都是单机限流,比如,我们配置业务API接口的限流是1000QPS,部署了10台,那么分给每台的限流就是100QPS,如果业务每台起一个长连,那么,对于业务而言,总共访问的QPS也就是400就触发了限流(4*100),这就说长链接更容易触发限流。
在我们实际的场景中,还遇到一个问题,我们在排查接入层nginx参数的时候发现,有一个参数配置的有问题:
1 | keepalive_requests=1024 |
这个参数具体含义可以查阅资料,一般而言,我们可以提高该参数的值更加有效的利用TCP连接,但是用在网关层就不合适了,这个值超过了单机限流的阈值,所以,无法实现将业务的长链接在整个接入层做负载均衡。
结论
分析了我们跟中台的网络模型后,运维也调整了keepalive_requests参数,
1 | keepalive_requests=32 |
这样,每个链接就可以在不触发单机限流情况下实现负载均衡。