再谈稳定性工作
最近一段时间都在做一些整个业务的稳定性工作,前面稍微写了核心链路的总结;C端的业务,稳定性是重点,但这方面的工作细节太多,比较琐碎,需要系统性的梳理一下。
整体考虑
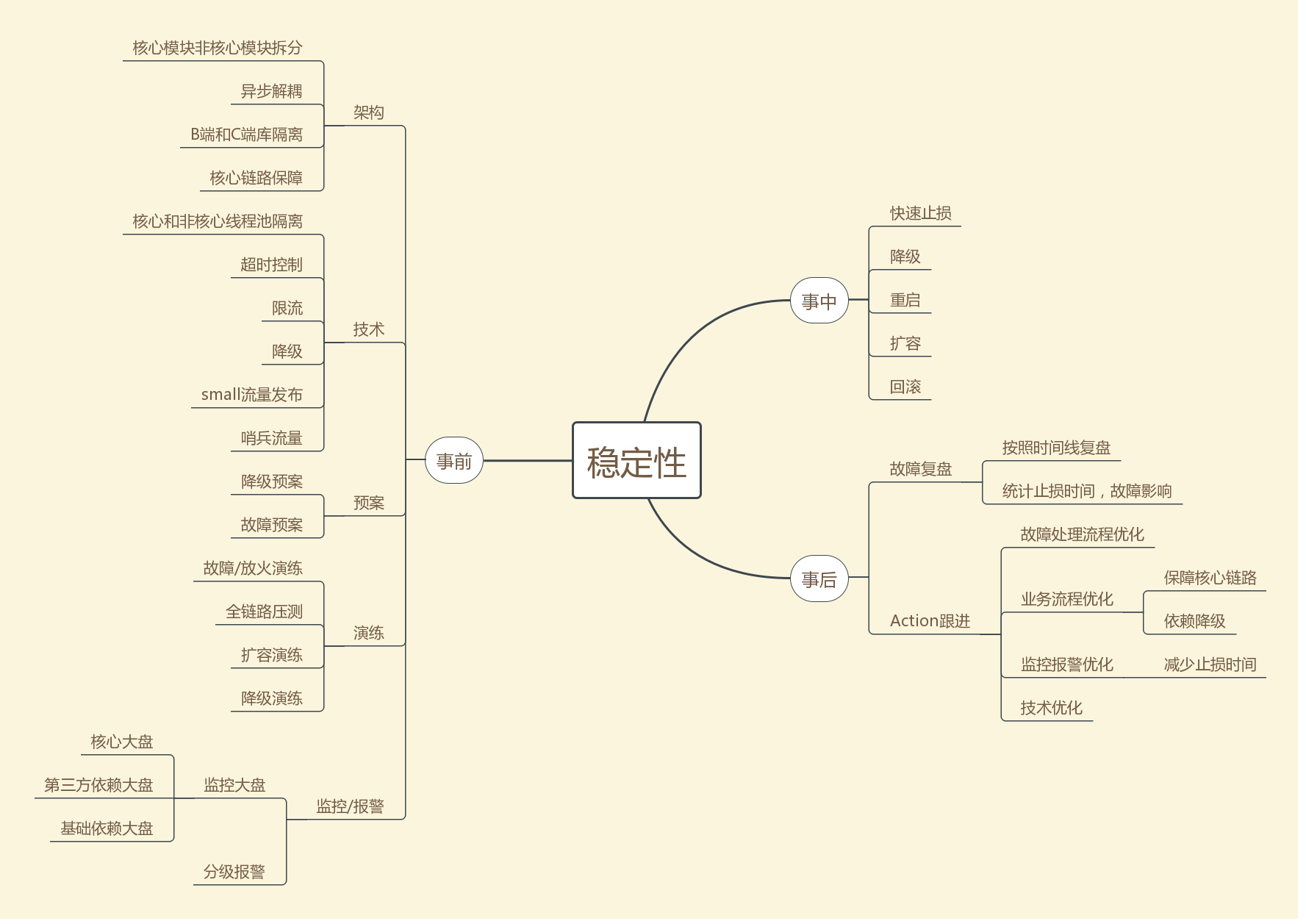
整体上,我们可以把稳定性的工作分为三个阶段:
- 事前:事前事稳定性工作的核心,一个团队应该按照月份,或者至少季度来周期性考虑稳定性工作
- 事中:事中的核心就是止损,不要在这个阶段想着定位问题
- 事后:事后在于复盘和优化,事后的Action一定要保证跟进和落地
稳定性意识
虽然单纯在技术上而言我们有好多可以做的,但是,其实最难的还是稳定性意识。大部分同学只关心业务,而很少关心稳定性工作,尤其是刚毕业或者刚开始工作的时候。所以,我们需要反复强调这方面的重要性。争取:
- 只经历几个P3故障就能让团队树立起稳定性意识
我们都不希望发生故障,但是实际中确实发现,单纯强调的效果并不理想,所以,最好的是出一两个不严重的故障之后,趁机把稳定性工作行程规范。当然,我们不能全部寄希望于此,我们还可以:
- 构建稳定性指标:梳理当前的线上稳定性问题,预估一个稳定性指标,在团队内部达成一致
- 纳入绩效考核:让大家逐渐形成稳定性的意识,不能闷头只做业务,要知道做了再多的业务,一旦出了稳定性问题,先前花大量精力通过各种拉新促活而留下来的用户,很可能就会因为稳定性问题导致的业务不可用而对我们失去信心。
当团队每个成员树立起稳定性意识之后,整个业务的稳定性工作推动就会比较顺利,每个人在写业务的时候,就会自觉的考虑:要不要先流?要不要降级?监控和报警配置了没?
稳定性闭环
稳定性工作一定要形成闭环,做事不能虎头蛇尾,一旦出了故障,就要复盘,复盘后就要制定Action,制定Action就耀跟进落地;除了具体故障的闭环,我们还应该举一反三,在整体上形成闭环:
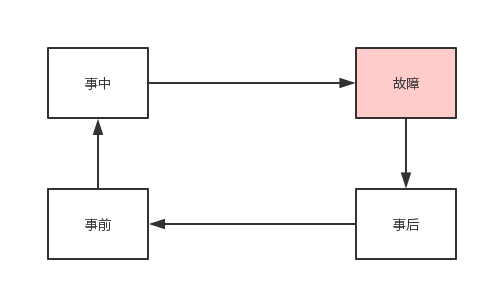
从故障开启复盘,做好事后的Action跟进,然后反思整体的架构和技术的改进点,在事前做好充足的预案和演练工作;这些工作会在故障发生事后的事中发挥巨大的价值:快速止损。我们不能完全排除故障发生的可能性,尤其是微服务之后,一个单独的业务线不可能完整的内部闭合,所以,我们要做好稳定性闭环,逐步优化我们的稳定性工作。
一些实践
在稳定性工作开展以来,收获不少,除了整体的架构和流程的收获外,有一些细节也比较重要:
- 全链路压测要慢慢的更加接近实际的场景:刚开始的时候,我们只是优先跑通全链路,后面就要开始丰富压测场景,使其更加接近于线上流量
- 做好周知和评估:压测的时候,按照流量比例做好对第三方业务的流量预估,做好周知
- 做好隔离:业务隔离,模块隔离,消息隔离,线程池隔离,数据库隔离,隔离是是保证核心业务稳定性的一大利器
- 做好演练:有些演练可能会比较简单,比如,打开一个开关,或者让运维扩容,但是,即使最简单的稳定性预案,也要周期演练。并且,每次演练做好周知和数据恢复策略;事实上,我们在演练的过程中踩过好多坑,幸好这些坑不是在线上被被暴漏出来。
- 稳定性周会:每周开一次稳定性周会,集中处理报警和稳定性工作进展。