关于分布式锁
看了两篇文章:1,2,主题是“基于Redis的分布式锁到底安全吗?”,作者翻译了分布式大神Martin Kleppmann和Redis的作者antirez之间就发生过一场争论,等有时间我也去看看原文,这里先总结一下文章里面的主要观点,以及关于分布式锁和fencing机制的几种实现。
看完后,我觉的Martin大神的几句话让我印象深刻,写在前面:
- Martin指出,RedLock本质上是建立一个同步模型基础上,而好的分布式算法应该基于异步模型(asynchronous model),算法的安全性不应该依赖于任何记时假设。在异步模型中,进程可能pause任意长时间,消息可能延迟,可能丢失,系统时间也可能出错(我遇到时钟漂移的问题),一个好的分布式算法,即使在非常极端的情况下,这些因素应该影响算法的安全性(safty property),只可能影响它的活性(liveness property),也就说好的算法不能给出错误的结果,顶多不能再有限的时间给出结果而已,像paxos,raft等
- Martin指出,即使我们拥有一个完美实现的分布式锁方案(带自动过期),在没有共享资源参与进来提供某种fencing机制的前提下,我们仍然不能够获得足够的安全性。后面我会结合Hadoop的fencing机制讲一下常见的fencing策略
分布式锁的实现
基于Redis的单key
获取锁:
SET resource_name my_random_value NX PX 30000
上面命令的含义:
- my_random_value是由客户端生成的一个随机字符串,它要保证在足够长的一段时间内在所有客户端的所有获取锁的请求中都是唯一的
- NX表示只有当resource_name对应的key值不存在的时候才能SET成功。这保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁
- PX 30000表示这个锁有一个30秒的自动过期时间
释放锁:
伪代码如下:
1 | if redis.call("get",KEYS[1]) == ARGV[1] then |
这段Lua脚本在执行的时候要把前面的my_random_value作为ARGV[1]的值传进去,把resource_name作为KEYS[1]的值传进去
肯定一堆问题,因为没有办法在网络环境保证原子性,详细的分析可以看看原文。
基于Redis多key的RedLock
antirez提出了新的分布式锁的算法:Redlock。上一个锁的问题,除了网络以及程序暂停等问题外,还有一个问题就是由Redis的failover引起的。
假如Redis节点宕机切换到slave节点,但是,我们知道数据复制是有延迟的,这就可能造成在failover的过程中丧失锁的安全性:
- 客户端1从Master获取了锁。
- Master宕机了,存储锁的key还没有来得及同步到Slave上。
- Slave升级为Master。
- 客户端2从新的Master获取到了对应同一个资源的锁
RedLock的基本思想就是通过多个Key的获取来避免failover的问题,大概过程:
- 获取当前时间
- 按顺序依次向N个Redis节点执行获取锁的操作
- 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间
- 如果最终获取锁失败则释放锁
详细的算法可以可以看看原文,总之,RedLock算法认为一个Redis Key不靠谱,那就是使用多个Key,获取多个Key的大多数的时候,认为获取锁成功;多个Key的获取增加网络延迟,于是利用本地时间来计算总的超时时间(这也就是被Martin喷的最惨的地方:依赖于本地记时的同步模型)
这个锁看起来就不靠谱,太过复杂而没有解决根本问题(程序暂停啊等),Martin的评价是:
neither fish nor fowl (非驴非马)
基于Zookeeper的临时节点
方案如下:
- 客户端尝试创建一个znode节点,比如/lock。那么第一个客户端就创建成功了,相当于拿到了锁;而其它的客户端会创建失败(znode已存在),获取锁失败。
- 持有锁的客户端访问共享资源完成后,将znode删掉,这样其它客户端接下来就能来获取锁了。
- znode应该被创建成ephemeral的。这是znode的一个特性,它保证如果创建znode的那个客户端崩溃了,那么相应的znode会被自动删除。这保证了锁一定会被释放。
借助于ZK的session机制来维持锁的持有状态,就不会遇到跟Redis一样的锁的有效时间的问题。但是,该方案(以及下面的方案和上面的两个redis的方案)都会遇到脑裂的问题:
- 客户端1创建了znode节点/lock,获得了锁。
- 客户端1进入了长时间的GC pause。
- 客户端1连接到ZooKeeper的Session过期了。znode节点/lock被自动删除。
- 客户端2创建了znode节点/lock,从而获得了锁。
- 客户端1从GC pause中恢复过来,它仍然认为自己持有锁。
要解决脑裂问题,就要依赖于后面要讲的fencing机制。
基于Zookeeper的临时有序节点
上面的方案会造成惊群效应,Hadoop上有一个更好的方案,另外,我看了下curator的源码,跟这个方案很类似。
- 在ZK上创建临时有序节点:locknode/lock-
- 获取该节点的所有children,只获取不监听该节点变化(避免惊群效应)
- 对children节点排序,如果当前节点是最小的节点,则获取锁成功,并退出获取锁流程
- 否则,调用exists退出并监听比自己小的下一个节点的变化。
该方案下,节点的移除只会唤醒一个客户端,避免了惊群效应。但也意味着,整个锁的获取是有序的,类似于Java本地的公平锁
Fencing机制
上面已经讲了,即使使用ZK来实现分布式锁,还是会面临脑裂的问题。Martin提出了使用fencing token的机制来保护被访问资源,下面我先总结下Hadoop的fencing机制,对比一下。
Hadoop的Fencing机制
Hadoop 2.0对NameNode引入了HA机制,整个HA的流程可以参考原文,我这里主要总结下Fencing机制。
下面是整体的高可用架构,Hadoop 2.0对NameNode增加了主备机制
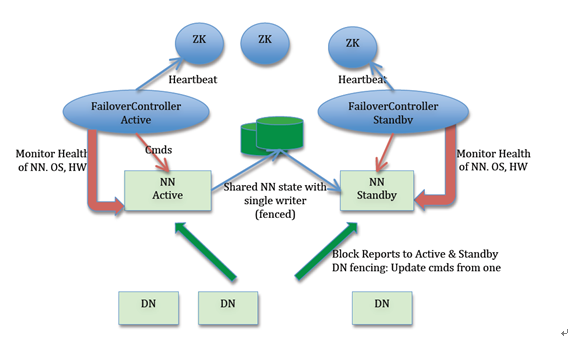
下面是主备切换的流程:
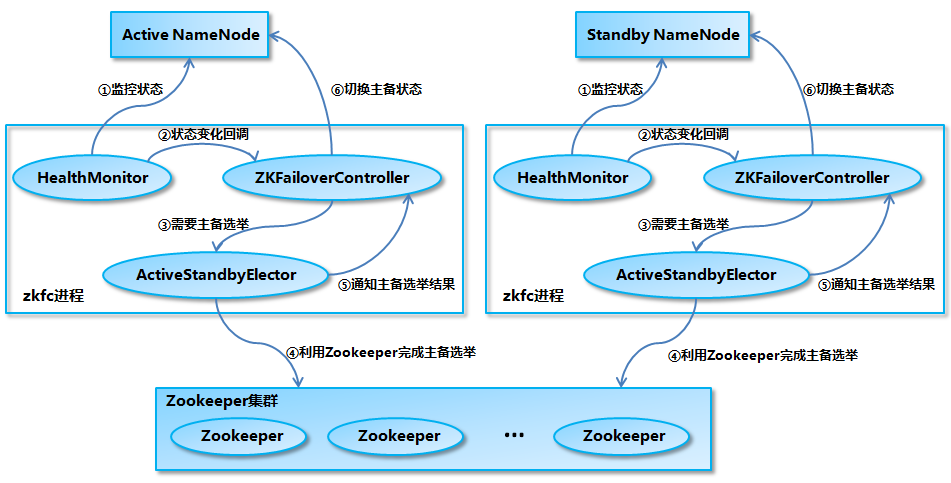
从该流程可以看出,NameNode选主依赖于ZK,就像上面流程,一旦出现Master假死,就有可能引起脑裂。那Hadoop是怎么处理的呢?
Hadoop的处理流程如下:

主要有下面几个步骤:
- Master被选为主
- Master会在ZK上写一个持久型节点,将自己的地址信息写在里面
- 如果Master正常退出,会删除持久节点;其他情况,Slave监控到了Master退出,会进入Slave激活的流程
- Slave首先会看一下有没有上一个Master留下来的持久节点,如果有,那么意味着老的Master可能处于假死状态
- Slave尝试将老的Master停掉(fencing机制),具体可以通过预留的rpc端口,ssh登陆,shel等
- Slave停掉老的Master之后,自己切换到Master状态
Fencing策略
对比于Matin提到的fencing token机制(受保护资源只接收最新token的访问),hadoop的fencing机制工程上更实用一些,不需要一个全局继增的token生成器。总的说来,fencing有两种策略:
- 将访问资源的Host给拦截掉。就像Hadoop的机制,出现脑裂的时候,会通过一种策略找到老的Master,然后干掉老的Master
- 将访问资源本身跟保护起来。访问资源访问的时候,需要通过类似于token(严格继增)的机制,将老的token访问给过滤掉。该方案可以借助于ZK的顺序节点,Master获取锁的时候,顺便把节点的id作为token。
结束语
建议大家看看原文,里面列举了好多case会造成分布式锁的失败。在一个分布式的环境里面,异步才是王道。