大流量下的反压问题
最近在梳理公司的大数据处理的流程,运维HBase的同事反馈我们中间件的链路收集日志(类似阿里的鹰眼)给HBase造成的压力最大,问我能不能优化一下。在优化的过程中,梳理了整个链路的反压处理,意识到在流处理,甚至在普通的大流量处理里面,这是一个很重要的问题,结合自己在消息系统的经验,在这里总结一下。
反压问题的场景
反压问题,说直白点就是当系统有压力的时候,我们怎么把这种压力反馈回去,然后,让请求自然而言的降下来,也就是让压力降下来。
只要稍微注意一下,反压问题在我们实际的应用中还是很常见的,例如:
- MQ消息消费:业务消费MQ的消息,处理后,录入到数据库里面。如果数据库出现性能下降,MQ应该降低消费速度
- Flink实时数据处理:将Flink实时处理的结果写入到HBase。如果HBase出现问题,Flink的处理速度需要降下来
- 甚至抢红包的业务,也可以看做一个反压的场景:大量流量过来抢红包,数据库IO出现瓶颈,那么,就应该减少放过来的流量
- 等等
总体来说,反压的场景可以归为两类:
- 单机反压
- 分布式反压
下面就两个场景分开讲一下。
单机反压
处理单机反压,一般借助于下面两个思路:
- 队列
- 延迟调度
队列的应用场景,一般是接收用户请求,接收异步消息等等,我们统称为异步task,如下图:
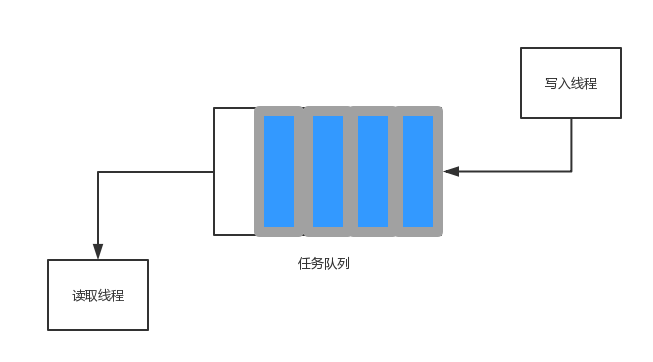
一个典型的生产者-消费者队列,在反压的场景下,很实用。例如,我们在提交线程池任务的时候,这样设计:
1 | threadPool = new ThreadPoolExecutor( |
当线程满的时候,通过SynchronousQueue自然而然的阻塞住任务提交,将速度降下来。
另外一个在单机的场景下,处理反压问题的就是延迟调度。我们通过线程池调度一个作业,然后,根据外部条件(例如,队列的大小,任务数)来动态修改调度的延迟时间,简化的处理代码如下:
1 | private class Task implements Runnable { |
上面模型的一个关键在于,线程池的调度不是以固定的速率进行,而是通过每次执行业务逻辑后得到一个反馈,进而影响到任务的调度。
分布式反压
在分布式场景下,各个节点通过网络进行沟通,当下游出现压力的时候,我们要通过网络反馈到上游,进行反压。在具体的分布式环境下,可以分为两类:
- 同步调用
- 异步调用
同步调用
常见的就是同步,或者业务刚开始的时候基本都是同步调用,成本低,实现方便,这个时候的反压机制是基于线程的:
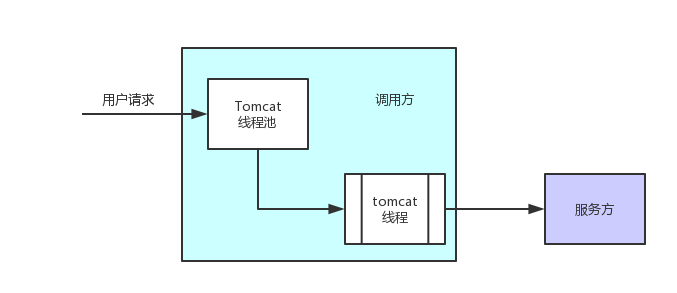
从接收用户请求开始,就为用户分配了一个线程,该线程直到同步调用完毕才被释放;那么,自然的,当服务方有压力的时候,服务的RT就会拉长,tomcat线程就会占用更长时间,那么,客户端可以连接过来的请求就会降下来。
这种反压方式最简单直接,但收益不大,调用方的cpu大部分时间在空等。
异步调用
当业务上升的时候,我们就会追求异步。异步模型的反压会相对麻烦很多,结合实际的场景,我们详细分析一下。
一种场景是服务的提供方,压力基本跟请求有关,典型的就是kafka,rocketmq以及vdianmq(我们自己的mq)这样的消息系统。
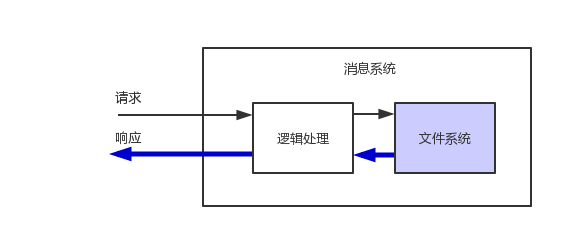
这类系统的特点就是:
- 系统压力来源于请求,因为是服务端嘛
- 响应和请求不对称,例如,请求可能几个字节,但是,响应却很大,几K甚至到M的字节
- 请求来源的网络环境千差万别,例如,有的部署在国外,有的是移动网络;这种请求下,加上响应和请求的不对称,请求端在一个或者重试几次,在可控的RTT内请求就到了服务端,但是,因为服务端的响应数据比较大,需要经过好多次网络重传,这就加剧了服务端的内存和带宽消耗。
这种情况下,我们控制反压的手段最自然的方式就是依赖于TCP的Buffer,SendBuffer满了我们就不写response了,或者就不接收新的请求了;ReceiveBuffer满了,请求自然不能建立连接,请求速度也就会降下来。
例如,在我们的消息系统里面,借助于Netty的水位线实现的反压机制:
1 | //配置水位线 |
可以看见,Netty对这种情况提供了很自然的支持:当write buffer满了之后,关闭Netty auto_read的feature,让请求速度降下来。
另外一种异步的场景,就是作为服务调用方。因为是异步的形式,我们更容易将服务端压垮:每次我们就发一个请求,不必等待返回值就接着处理下一个请求。这种情况下,当然也可能借助于上面的例子:使用Netty的水位线来控制,这种情况就不举例子了。下面以HBase为例,看看在使用HBase的时候,怎么处理反压。
我们的日志实时处理系统,会将分析的结果写到HBase里面,那么写的时候自然要考虑压力问题:
1 | //配置HBase的反压的参数 |
看起来没有Netty处理的那么自然,但是也代表着一种处理模式:异步发送的时候,我们要关注发送后的状态,不要异步发送完了就什么也不管了。
小结
反压问题是一个整个链路的问题,我们不能只站在服务提供方或者调用方来考虑问题,要仔细梳理整个环节,看看哪一部分对压力的处理没有考虑周全,整体优化。